There are millions of different ways to calculate keyword density. It is a big problem because without exact specification your 4% might be very different from someone else’s 4%.
In Cora the density reporting is a research tool so we can try to better understand density’s role in search.
Some definitions:
A
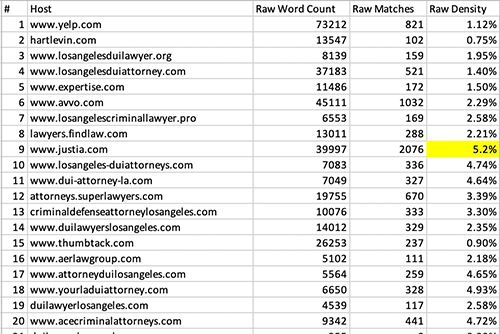
raw density is the most inclusive form. We count matches and words anywhere they occur on the page. No part of the page is excluded.
A
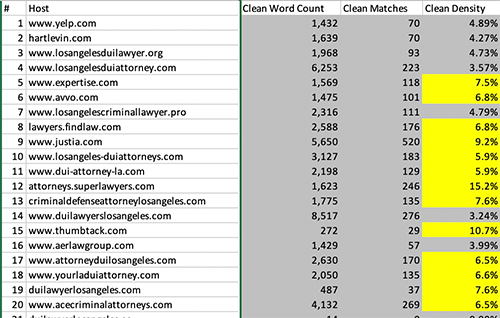
clean density is the most exclusive measurement. We delete the head block, scripts, styles, comments, and HTML tags. Then from the context text that is left over we count matches and words. So it is the most exclusive measurement possible.
Different people’s implementations of density may include or exclude things like title text, meta description, etc. Based on all the parts you can include or exclude there are probably about 8 million different ways to calculate keyword density hence the apples to oranges problem.
So in Cora we give you the most inclusive measurement ( RAW ) and the most exclusive measurement ( CLEAN ) and most peoples implementations will fall on the spectrum between the two. When most people think of keyword density they usually envision an implementation closer to the clean end of things.
The problem gets further complicated by word counts. Google has admitted to using a stop word list… these are words that are so common they have no unique contextual value so Google doesn’t waste time indexing them. They are words like he, a, an, if, the, etc.
As a result of Google’s practice, Cora does not include 1-2 letter words in word counts usually because Google probably isn’t either. Changing the word count changes the density because density = matches / word count.
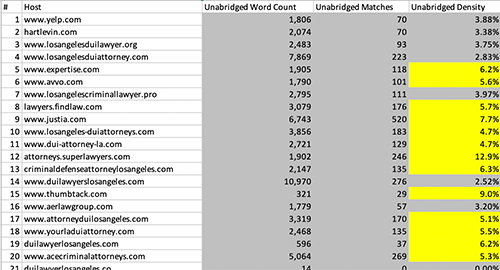
So in the report “Unabridged” means “Clean but including 1-2 letter words”
Each type of density in the report has 3 or 5 columns:
Word Count, Match Count, Density
OR
Raw Matches, Clean Matches, Unabridged Density, Raw Density, Clean Density
The data with 3 columns uses all keyword variations in the calculations.
The data with 5 columns is on a single word basis and you can scroll to look up density information for any of the keyword variations.
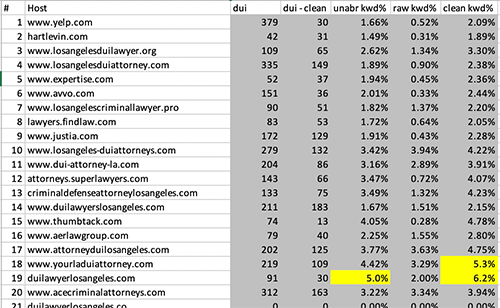
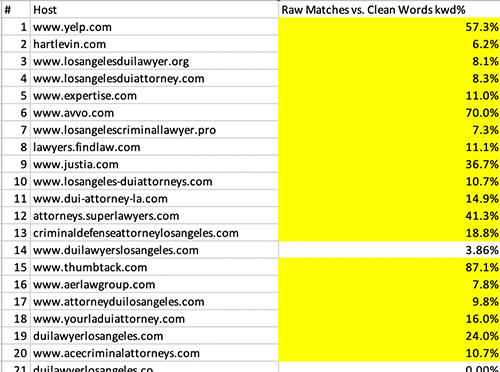
The last part of the report to explain is : Raw Matches vs. Clean Words kwd%
This is the MOST AGGRESSIVE calculation of density. It uses the RAW match count and the CLEAN word count. It is a great indicator of who is trying to cheat the system with tricks.